OpenAI / Google / 雲端平台
模型訓練與推論需求擴大,帶動 GPU cloud、hyperscaler 與自建資料中心投資。
AI infrastructure supply chain
這張 infographic 把白板上的想法整理成一條因果鏈:模型與雲端資本支出拉動 GPU / ASIC,接著推升先進製程、HBM、CoWoS、PCB/CCL、電源、散熱與光通訊,最後回到資料中心電力與建設能力。
decision map
模型訓練與推論需求擴大,帶動 GPU cloud、hyperscaler 與自建資料中心投資。
GPU 仍是主軸;Broadcom、Marvell 類 ASIC 則承接大型客戶自研晶片與網路晶片需求。
高階 GPU / ASIC 需要先進節點、先進測試與良率管理。
AI 加速器效能受記憶體頻寬限制,HBM 供給成為核心約束。
GPU、HBM 與基板要在同一封裝內高速互連,封裝產能決定可出貨量。
伺服器 ODM、機櫃、背板、電源模組與液冷方案把晶片轉成可運作的 rack-scale 平台。
叢集規模越大,GPU 之間的資料搬移越關鍵,交換器與光模組需求同步上升。
AI rack 功耗上升,配電、備援電力、變壓器與電網接入成為後段瓶頸。
高功耗 rack 需要液冷與熱管理,資料中心機房設計也要同步升級。
layers
OpenAI、Google、Microsoft、Meta、AWS、Oracle 等需求端決定總量。關鍵不是單一產品,而是訓練、推論、企業 AI 與 GPU cloud 的資本支出節奏。
NVIDIA 供應通用 GPU 平台;大型雲端客戶同時推動 ASIC,以改善成本、功耗與供應彈性。Broadcom、Marvell 等角色因此變重要。
AI 晶片的真正限制常落在先進製程、HBM 與 CoWoS 類先進封裝。只要其中一段不足,最終 GPU 或 ASIC 出貨就會被卡住。
高階 AI server 需要更高層數 PCB、低損耗 CCL、retimer、power management 與背板設計。這是白板上「technical」區塊的重要含義。
廣達、緯創、緯穎、鴻海、Supermicro、Dell 等把晶片、板材、電源與冷卻組成可交付系統,交期與產能反映下游真需求。
AI rack 功耗密度上升後,電力、散熱、機電工程、備援電源與光通訊都會變成擴張限制。這也是供應鏈從半導體延伸到工業與公用事業的原因。
bottleneck signals
看大型雲端或 AI 平台是否給出多年資本支出、供應協議、資料中心租賃或 ASIC 專案。越具體,越能往上游追供應鏈。
HBM、CoWoS、低損耗材料、電力接入、液冷與光通訊如果擴產週期長,就容易出現價格、稼動率與訂單能見度上修。
從單機 server 走向 rack-scale、從銅纜走向光互連、從氣冷走向液冷,通常會改變誰有議價能力。
先看營收與毛利率,再看庫存、交期、資本支出與客戶集中度。供應鏈敘事若沒有財務驗證,容易只是題材。
role map
source board
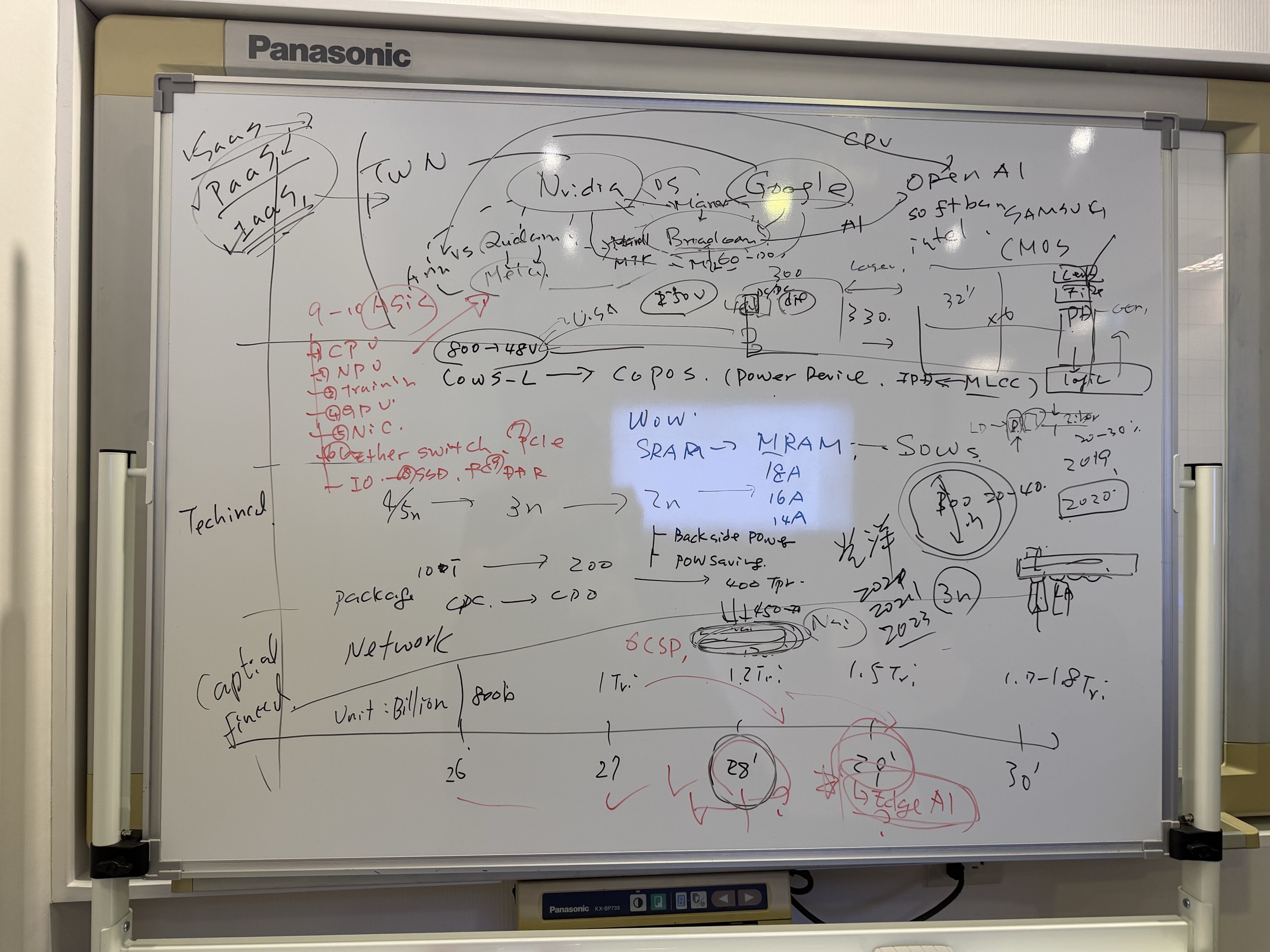
左側像是在列出供應鏈分類:GPU、NPU、training、GPUs、network switch、PCIe、SSD、DDR、IO 等。中間把 NVIDIA、Qualcomm、Broadcom、Google、TSMC、CoWoS、CoPoS、HBM、SRAM/MRAM 與 power saving 串起來。右側則延伸到 OpenAI、軟銀、CMOS、laser、light、32 吋與光通訊等概念。
整理後的主線是:AI 需求不是只買晶片,而是迫使整個 data center stack 重新升級。越靠近瓶頸、越難被替代、越能在財報中驗證的節點,越值得深入研究。